
Weakness Chaining in the AI Attack Surface

Pamela Weaver
Securin Team


Dec 12, 2025
When GenAI first entered mainstream software development pipelines, conversation quickly centered around novelty: hallucinations, synthetic media, prompt injection. Security teams largely viewed these anomalies, threats to be isolated from the traditional CVEs and CWE chains defenders already understood.
But that framing missed the real shift already underway: GenAI systems haven’t replaced traditional vulnerabilities, they’ve made them more dangerous, functioning as a new connective layer that reconfigures how classic weaknesses behave in the wild. And attackers are already exploiting that flexibility.
CWE Weakness Chains are multiple low-risk software weaknesses combined to form a more powerful attack path that attackers can exploit. Securin analyzed 250 CWE chains, drawn from 2,700+ known exploited vulnerabilities (KEVs) and 19,400+ documented exploits. What we found: direct evidence that attackers are incorporating GenAI into classic exploitation paths. Two new CWEs - CWE-1427 (prompt injection) and CWE-1426 (improper input validation) - have already emerged as key components in these cross-domain chains.
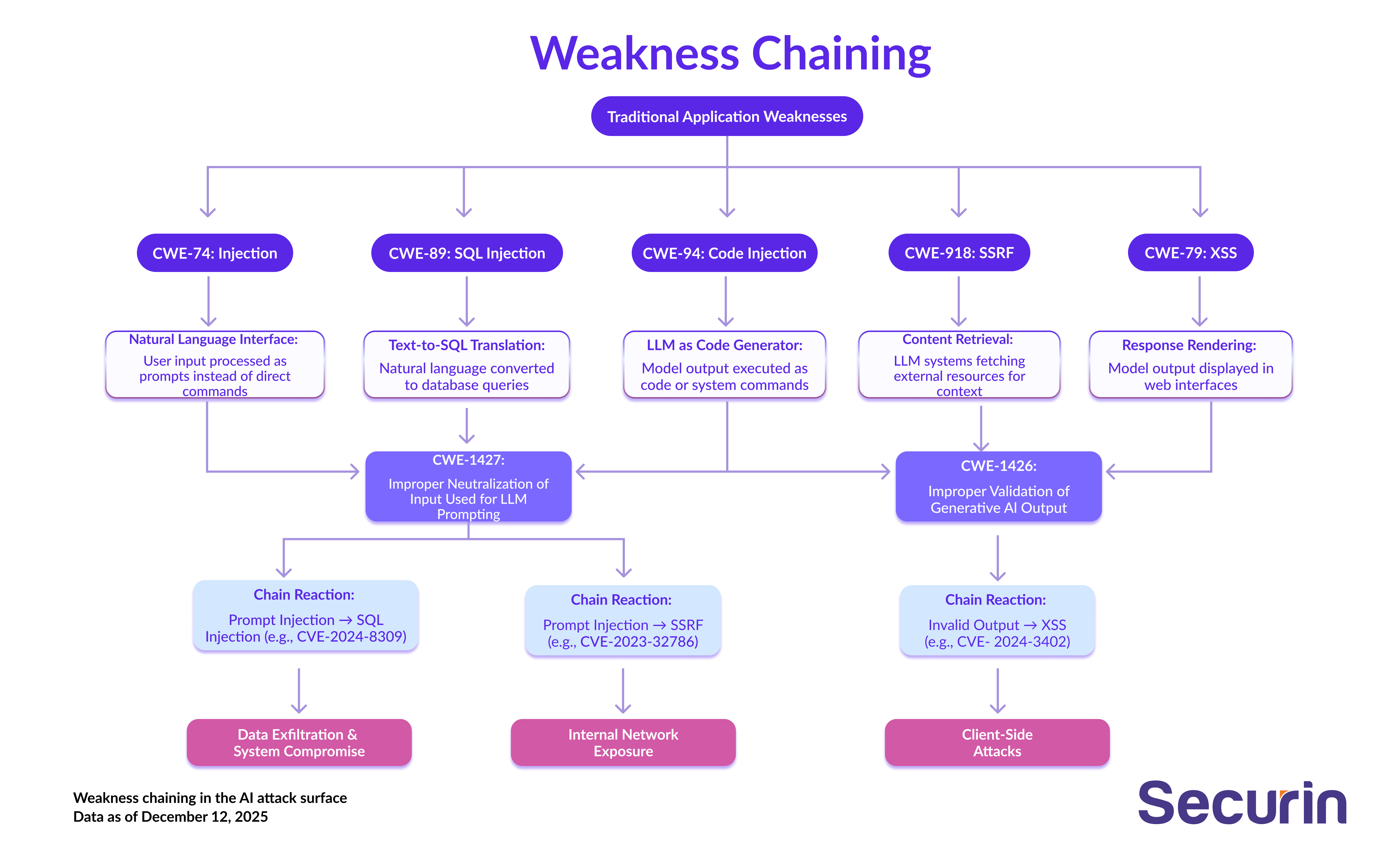
Rather than re-invent the wheel, adversaries are reusing the building blocks of known chains, and inserting AI systems into the middle.
So, how are they doing this, and what do defenders need to know?
Semantic Chaining: How AI Becomes the Adversary’s Middle Layer
Adversaries aren’t treating AI as the end target, they’re embedding it mid-chain - using language models as functional components inside classic exploitation flows.
Securin’s data shows a clear pattern: prompt injection no longer ends at model manipulation; it’s the beginning of a multi-stage exploit.
Language models now act as semantic bridges, interpreting attacker-crafted prompts and generating outputs that directly trigger downstream vulnerabilities. Two new CWE classes - CWE-1427 (prompt injection) and CWE-1426 (improper input validation) - define this shift. And these patterns are already operationalized:
• CVE-2024-8309: Prompt injection -> LLM-generated SQLi (SQL injection)
Here, the attack vector is natural language -> model inference -> structured query exploit.
What’s happening: The LLM acts as a dynamic SQL payload generator.
• CVE-2023-32786: Prompt injection -> SSRF (server-side request forgery)
The attack vector here is the prompt manipulating the model to fetch internal service data.
What’s happening: The LLM is acting as a trust-boundary pivot tool.
• CVE-2024-3402: Invalid output -> Persistent XSS (cross-site scripting)
The attack vector for this is the model generating HTML or JS content that isn’t sanitized before render.
What’s actually happening: The LLM is the source of executable client-side content.
Each of these chains starts with a known CWE. Each ends in a known outcome. But in between, an LLM is doing the connective work: reshaping inputs, building payloads and crossing boundaries that static systems would not.
These aren’t theoretical, or red-team demos. They’re working exploit chains in production systems where AI expands - not replaces - the logic adversaries have used for decades. The LLM layer adds flexibility, obfuscation and scale, re-defining the flow of exploitation through language rather than code.
AI as Logic Glue: The New CWE Transitions
That Change Everything
Traditional vulnerability chains rely on predictable transitions, such as memory corruption leading to code execution, or broken access controls leading to privilege escalation. It’s a well-understood mechanical flow, bounded by execution layers.
GenAI breaks that pattern. In AI-powered chains, the transition is semantic:
- The attacker controls the intent.
- The model interprets and amplifies that intent.
- The system executes the result.
What does that look like in real terms?
LLM-driven systems introduce a semantic transition point inside the chain - an interpretive layer where attacker intent is translated into system action using natural language. Instead of moving directly from one technical state to another, the chain now flows through a model that re-writes the payload, restructures the request or generates executable content.
This structural shift in chain behavior now has a formal CWE footprint:
CWE | Name | Role in Chain |
CWE-1427 | Improper Neutralization of Input Used for LLM Prompting | Chain initiator (Prompt Injection) |
CWE-1426 | Improper Validation of Generative AI Output | Chain amplifier (Semantic payload propagation) |
These two CWEs define the new connective tissue in mixed-domain chains:
CWE-1427 captures the moment where natural language becomes the entry point - allowing an attacker’s prompt to redirect model behavior.CWE-1426 captures the moment where model output, left unvalidated, becomes a conduit for downstream exploitation.
Together, they formalize a shift from purely syntactic transitions (input -> parsing -> execution) to semantic transitions (intent -> interpretation -> action). And that semantic step - unique to GenAI - is now the glue binding traditional vulnerabilities into more fluid, harder-to-detect chains.
This brings several advantages for adversaries:
- Greater ambiguity makes detection more difficult.
- Outputs vary across users, systems or prompts, reducing repeatability for defenders.
- The model’s role as a logic engine gives attackers a programmable intermediary between input and exploit.
These dynamics flip typical expectations: in most environments, longer exploit chains mean more fragility. In AI environments, longer chains can be more stable because the model can maintain consistent logic across transitions.
Product Categories at Risk
These aren’t isolated cases. We’re seeing patterns by product category, where AI enables new exploit combinations across familiar interfaces:
Category | Common AI-driven chain types | Risk factors |
LLM-Integrated Web Apps | Prompt Injection → XSS/SQLi | Dynamic rendering of model output into UI or DB |
Database Systems with AI Assistants | Prompt Injection → SQLi | LLM-generated queries from user prompts |
Enterprise AI Platforms | Prompt Injection → SSRF / Output Abuse | Lack of output validation, deep system integration |
Across these environments, the pattern is consistent: LLMs create pathways between existing weaknesses that were not previously linked.
The Chain is the Threat: What Defenders Need to Understand
Inserting GenAI into the middle of exploit chains doesn’t just expand the surface area, it changes how adversaries move through it. As we’ve seen, in AI-enabled systems, the value isn’t in the weakness - it’s in the connection.
Prompt Injection (CWE-1427) might seem trivial in isolation. But if it leads to a command injection or internal network access, its severity changes drastically. Output validation failures (CWE-1426) might look like UI issues—until they enable exfiltration or code execution.
The data shows clearly: AI systems now act as functional components of exploit chains.
Three shifts stand out from Securin’s data, each with immediate implications for how defenders need to think about risk.
1. The model isn’t the target, it’s the tool
As we’ve seen, prompt injection has matured, it no longer stops at manipulating model behavior. In the chains observed by Securin, models are used tactically, to generate payloads, transform input or cross a boundary that static logic wouldn’t allow.
This makes LLMs an active layer in exploit paths - not a vulnerable component to harden in isolation, but a live interpreter that adversaries have built into their strategy.
Bottom line: Security teams stop thinking of GenAI as a ‘box’ with edges. It’s a bridge connecting input to execution, often invisibly.
2. Chain transitions are now semantic, not just mechanical
As we’ve seen, classic CWE chains flow in code. One weakness leads into another through control flow or memory state. But GenAI systems break that pattern. They inject a semantic step where meaning is inferred, rephrased, or transformed - often in ways that evade detection.
In the examples we’ve looked at - SQL injection, SSRF, persistent XSS - the root vulnerability isn’t just that the LLM was manipulated. It’s that the downstream system trusted what it said. That shift from natural language to executable input is the part defenders can’t afford to overlook.
Static scanners and signature-based tools aren’t built to trace these kinds of transitions. Detecting them means following the flow across systems, through model outputs and into the execution context they ultimately shape.
3. The new CWEs aren’t edge cases, they’re foundational
CWE-1427 and CWE-1426 aren’t edge-case tags for AI researchers. They’re structural indicators of how GenAI changes the shape of exploit chains:
CWE-1427 is where the chain begins: attacker input passed to a model without neutralization.
CWE-1426 is where the chain extends: model output passed on without validation or boundary enforcement.
Both CWEs formalize what’s already happening in the wild. And both demand upstream handling - in secure design, in model integration and in the assumptions developers make about “trusted” systems.
If those assumptions go unchallenged, GenAI won’t just introduce new risks. It will keep reconnecting old ones in ways that are harder to spot, harder to predict, and faster to weaponize.
Recommendations for Defense
Defenders should respond not by isolating AI issues into a separate category, but by integrating AI-aware CWE chaining into their broader vulnerability strategy.
Immediate actions include:
• Treat CWE-1426 and CWE-1427 as chain-critical vulnerabilities.
• Map where LLM input and output intersect with execution layers (e.g., SQL engines, renderers, request handlers).
• Flag common chain pairings, especially involving Injection, Memory Safety, or Access Control.
• Re-evaluate triage models: a “medium” CWE becomes high-risk when it reliably initiates or amplifies known chains.
GenAI Doesn’t Need New Weaknesses, It Makes Old Ones Stronger
Securin’s data underlines the new reality: attackers aren’t building entirely new chains. And they don’t need to, when they can re-purpose the ones they already understand, replacing brittle links with more flexible, generative ones. CWE-1427 and CWE-1426 are now established components in these patterns.
For defenders, this is more than a question of model hardening or AI red teaming. It’s about building an understanding of how generative AI logic re-wires existing vulnerabilities, and how it fits into chains we already thought we knew.
Until defenders start tracking those connections system-wide, adversaries will keep getting there first.
Share this post on:


